|
The goal of my final project is build a platform that can be a guide for learning-while-doing-projects (Project Based Learning, PBL). The prototype has two parts, the project search and the learning search. For the last month I have been mainly working on the project search: collecting data from projects (MakeMagazine, Hackster, Instructables), cleaning and processing the data, experimenting with different language models such as ELMO and BERT (based and large) to find similarities between projects, build a pipeline that will transform the 320,000 articles into tf.records, create a process that makes it easy to compute data, and planing a process for presenting the results. 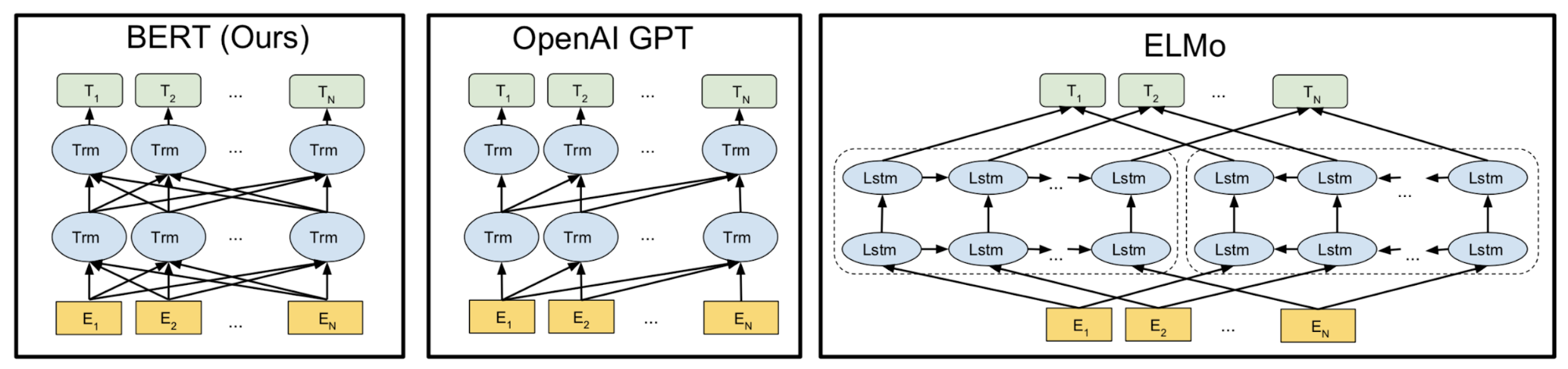 Image source: original paper How to decide what model use? Well, weeks ago I started with a very simple NLP technique, bag-of-words. The results with bag-of-words weren’t that promising, I was thinking of moving to something more computational sophisticated and decided to ask my mento Kai and Alec from OpenAI, the suggestion was to try a model and TFIDF frequency. I found that ELMO can could give me easily the embeddings I needed using tensorflow hub. I tried with very few articles and the results were ok, the method seemed to find articles with similar words but it wasn’t better than the website searches and it was awfully slow. As I stated in my last post I spend some time creating a pipeline for all my data so I could try ELMO with all the data and try to optimize the search. At that point I decided to try BERT base, again using the tensorflow hub I got the embedding for most of my data ~6 million embeddings and used faiss to compute the search among the embeddings. Results were still not as good as the websites so I decided to use BERT large, at this point while talking to my mentor Kai he suggested to try GPT2 (which I was planning to do), the argument is that GPT2 is trained in data (reddit) that contains words that are relevant to my dataset (arduino, 3D printer, laser cutter, raspberry pi, etc). While I was thinking about that implementation I found Passage re-Ranking with BERT. 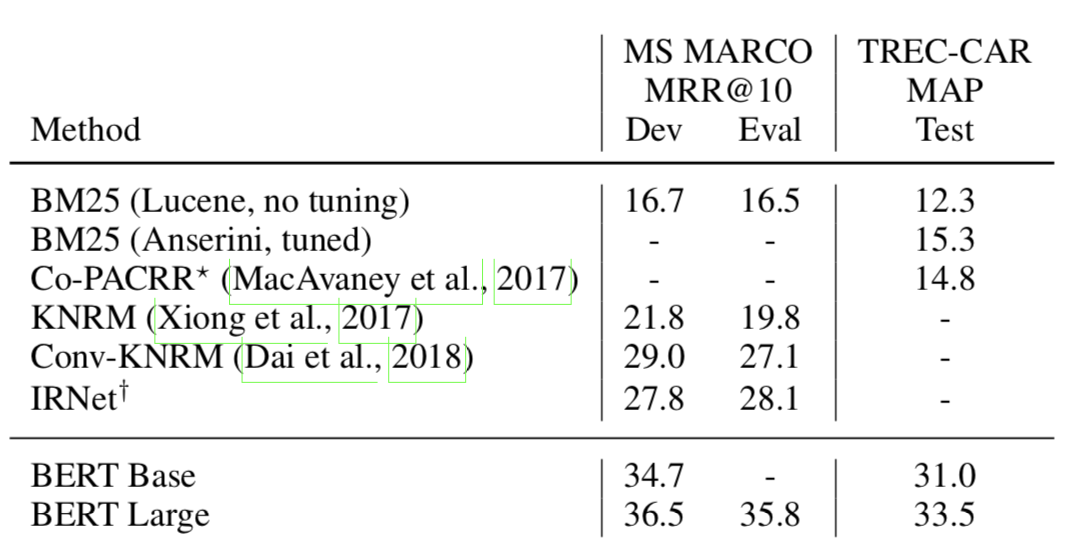 After experimenting with ~6,000,000 embeddings, faiss library (a library for efficient similarity search and clustering of dense vectors) and more, I believe a good direction is to implement the process described in this paper Passage re-Ranking with BERT. This paper is the SOTA re-implementation of BERT for query-based passage re-ranking. They trained their model with two datasets that resemble the form of my dataset and retrieves passages similarities. Give that my project wants to retrieve projects that are similar to the one the user wants to do, I think this is a great direction.
Even when the paper is focused on using BERT for re-Ranking, the whole process has three steps that help filtering the passages.
Using elastic search I decided to implement the first step too, mainly because independently of which model I end up using (BERT or GPT2) I can’t compute everything on 6 million embeddings and have a reasonable runtime. Well, now is me against the clock, wish me luck!
2 Comments
This week I used my new data, 70,000 (from the 300,0000) articles from Instructables to play with ELMO, TF-IDF and perform a Cosine Similarity. The results were much better! While making my data "trainable" I read a lot of articles that explain how cleaning and massaging the data can be 80% of the work in ML. This was a great lesson. Overall process:
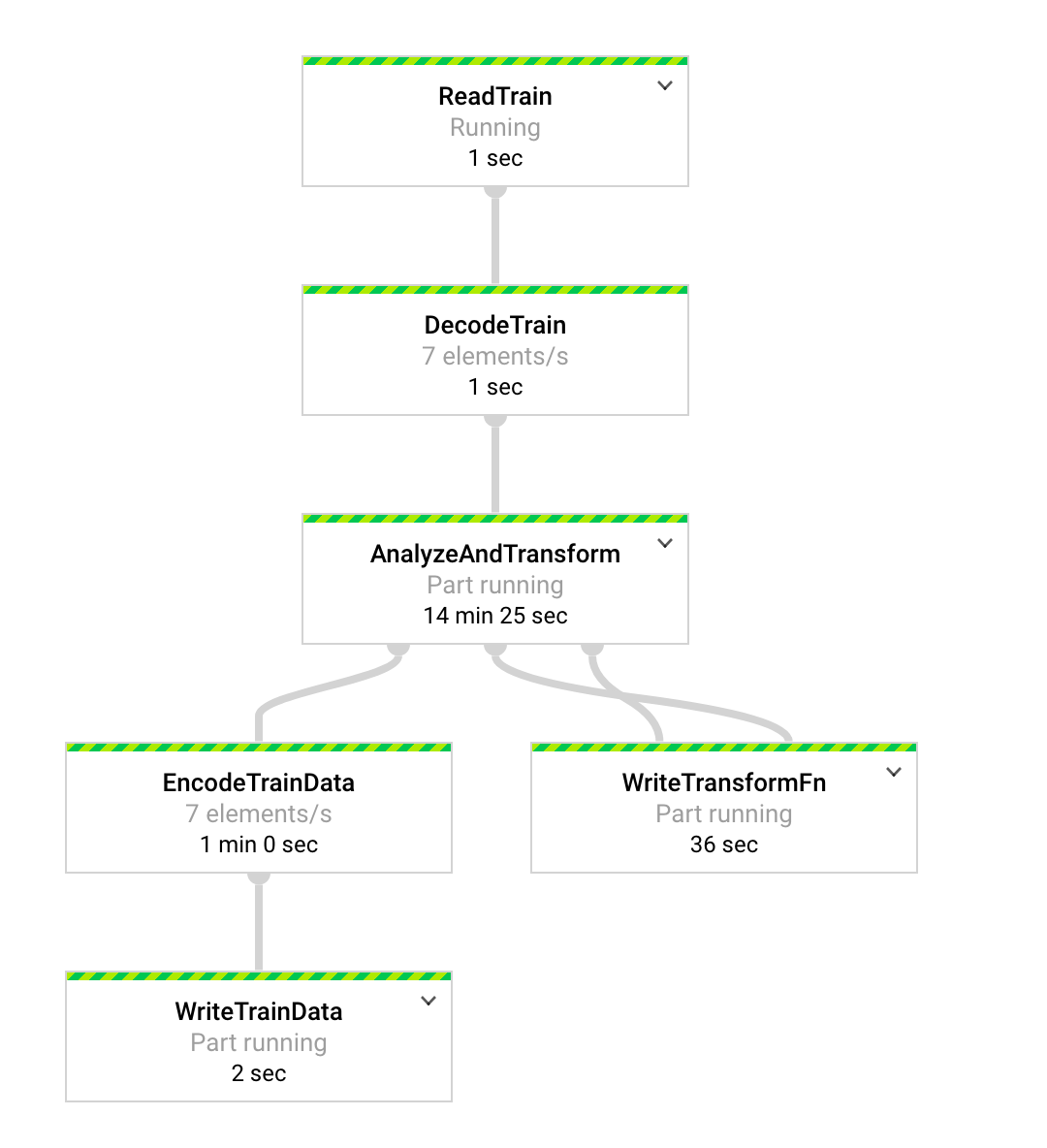
 I used tf.transform, tf.record and tf.example for the last three steps (preprocessing , design a dataset, load it and store it). I picked tf.transform and tf.record (tf.example is part of tf.record), because I wanted to learn something that was easily scalable, could integrate with my colab notebook, allow for parallel processing and monitoring.
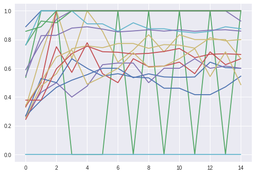
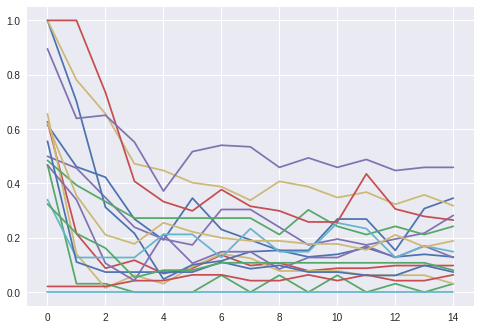
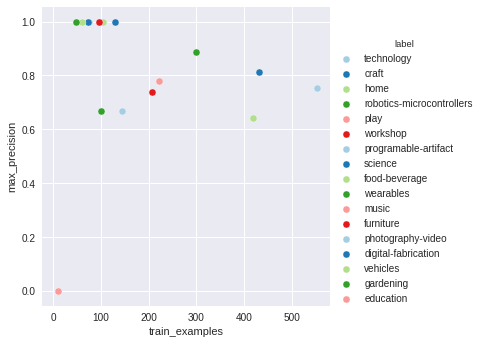
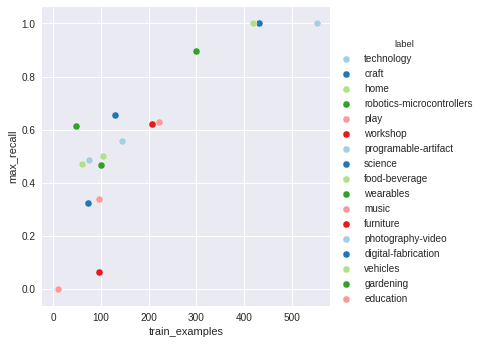
 Last week I created a bag-of-words as a feasibility exploration, this week I wanted to train a word-to-vect, but before I started it I realized a I had a bug on my bag-of-words and that's why the results were good. After fixing the bug the results weren't that great. I decided to try another experiment to understand better why my results were not good. So I created a sentence embedding of 50 dimensions, the results weren't that good either so I tried a sentence embedding with 180 dimensions. Still not that great. I plotted some of the results to understand better the problem.
The graph on the left is the validation set precision per epoch. The graph on the right is the validation set recall per epoch.
Reading several articles I realized that my project-category labels were not useful. Before I planned how to processed next I decided to do another experiment, this time of picture comparison. This will tell me how feasible could be to extract the information I need from the users' pictures. Using inception_v3 I created embeddings per picture, concatenated them into a vector and used that to compare pictures.
I need better data. So I decided to do some scrapping and get it. While my scripts are running I'm doing more data analysis to figure out what's the best way to classify the data given the information I can extract and the labels I can create.
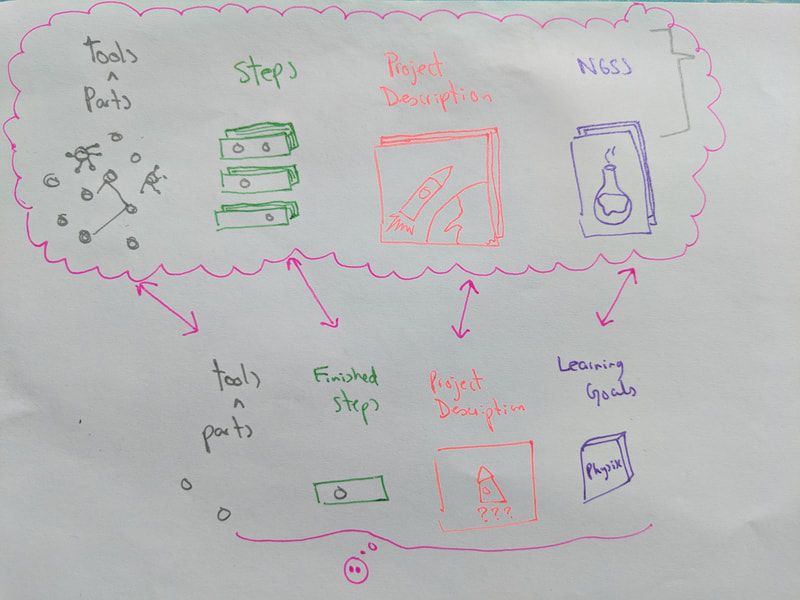
Rational Research tell us that one of the best methods that helps humans develop enduring understandings is the application of knowledge into a project (a form of project-based learning). When we apply what we know into a project we learn it deeper, we can recall it later and it becomes a tool we can keep applying. Schools don’t use this methodology, and one of the main causes is that it’s very hard let each student to create a unique project because of teachers’ bandwidth. The few schools that try to use project-based learning use it either as a toy project that the teachers ask students to do and that in most cases has nothing to do with how that knowledge is use in the real world. Or as a separate class called “making” where students create their own personal projects but it’s normally completely disconnected from formal learning. Even when both activities are steps into the right direction, the first type of activity is much less engaging, real, and doesn’t support the development of identity and creativity while the second one is less about applying knowledge and more about letting the kids use their hands and creativity in a less structured way. Proposal After training teachers in project-based learning all around the world and be in the founding team of a school where learning is 100% project-based learning (PBL) I learned that there is a list of things that can substantially help teachers and students to do PBL. The first is to know what kind of projects can be done with a specific set of tools, materials and time, the second is what skills are necessary for a student to be able to do a project, the third what knowledge will be applied in doing such a project and finally what can be done when a stuck on an specific part of project. But even if we have these information available for teachers it’s very time consuming for the teacher to be looking at all these information per student’s project. To give more agency and support the development of students’ independency I propose the develop of a webapp, Cielo, that students can use by themselves. Cielo will ask the user for at least 6 pictures of the current status of the project, a description of the overall project, a description of the current status, the category of the project and the tools and material. Using picture captioning, supervised learning and NLP, Cielo will return a list of projects that are similar to the one the student wants to make, a list of resources for the skills needed to develop that project, a list of resources based on the Next Generation Science Standards related with the scientific ideas of the project and the caption in English for their pictures. The webapp is intended to work even when with very little text, as long as there are enough pictures. In this way even young children or non-English speaker children can use Cielo. Data: Pluming v1 I’ll be using articles from Make Magazine (thanks a lot to Dale for it), Hackster and Instructables. The data are articles that explain how to make different types of projects, from IoT, to cooking, arts-and-craft or robotics. The projects vary on time, expertise, materials, skills, tools and topics. All of them have pictures, a description of the project, a category and a list of steps to make the project. I started with Make Magazine data because they gave me an XML file (thanks again!). So I parsed all the fields I cared about (tools, description, steps, conclusion, urls of pictures, level, categories, and duration of the project), and decided to use only the published articles (~2750). I realized that some of the labels were too general or didn’t correspond to what I needed. I created my own labels, map some of the current labels into them and relabeled around 900 articles. I’ll be using the pictures to get some information about the category of the projects and the different parts of the process the project. I also want to caption the pictures and use that information. Finally, I’ll be using the text to also predict the category and the parts of the process of the project. Text v1
After parsing all the text I wanted to create a simple model, a Bag of Words (BoW). My text is not all clean so the model BoW can show me how good the data is. I used Keras and Spacy to train a very simple model with two dense layers and adam as optimizer. The accuracy was from 0.2219 to 0.6760 and the loss started as 4.8035 to 1.4918 after 100 epochs. Given that there are 20 labels and it’s a multilabel unbalance set of data it’s not that horrible. |