|
The goal of my final project is build a platform that can be a guide for learning-while-doing-projects (Project Based Learning, PBL). The prototype has two parts, the project search and the learning search. For the last month I have been mainly working on the project search: collecting data from projects (MakeMagazine, Hackster, Instructables), cleaning and processing the data, experimenting with different language models such as ELMO and BERT (based and large) to find similarities between projects, build a pipeline that will transform the 320,000 articles into tf.records, create a process that makes it easy to compute data, and planing a process for presenting the results. 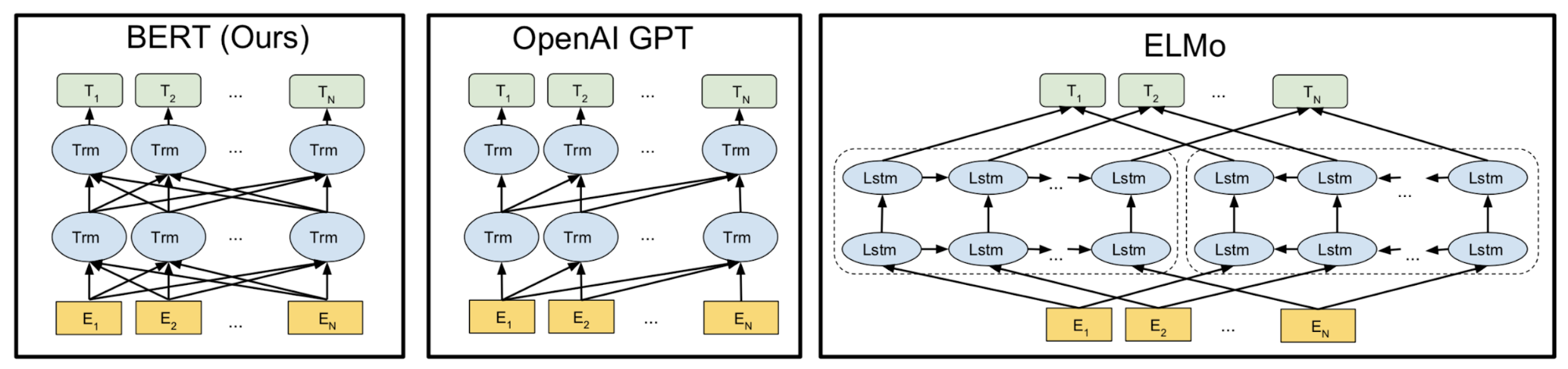 Image source: original paper How to decide what model use? Well, weeks ago I started with a very simple NLP technique, bag-of-words. The results with bag-of-words weren’t that promising, I was thinking of moving to something more computational sophisticated and decided to ask my mento Kai and Alec from OpenAI, the suggestion was to try a model and TFIDF frequency. I found that ELMO can could give me easily the embeddings I needed using tensorflow hub. I tried with very few articles and the results were ok, the method seemed to find articles with similar words but it wasn’t better than the website searches and it was awfully slow. As I stated in my last post I spend some time creating a pipeline for all my data so I could try ELMO with all the data and try to optimize the search. At that point I decided to try BERT base, again using the tensorflow hub I got the embedding for most of my data ~6 million embeddings and used faiss to compute the search among the embeddings. Results were still not as good as the websites so I decided to use BERT large, at this point while talking to my mentor Kai he suggested to try GPT2 (which I was planning to do), the argument is that GPT2 is trained in data (reddit) that contains words that are relevant to my dataset (arduino, 3D printer, laser cutter, raspberry pi, etc). While I was thinking about that implementation I found Passage re-Ranking with BERT. 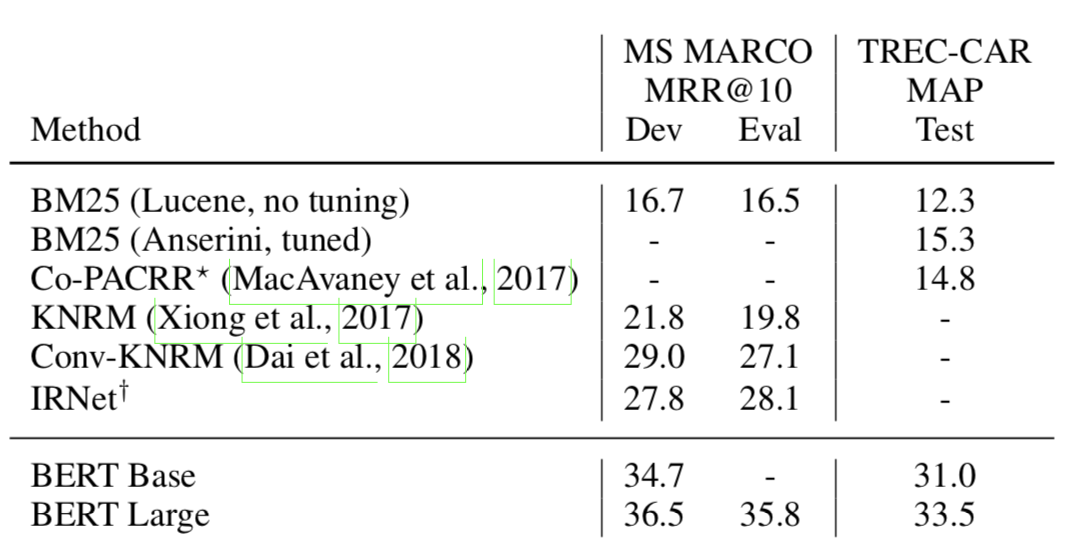 After experimenting with ~6,000,000 embeddings, faiss library (a library for efficient similarity search and clustering of dense vectors) and more, I believe a good direction is to implement the process described in this paper Passage re-Ranking with BERT. This paper is the SOTA re-implementation of BERT for query-based passage re-ranking. They trained their model with two datasets that resemble the form of my dataset and retrieves passages similarities. Give that my project wants to retrieve projects that are similar to the one the user wants to do, I think this is a great direction.
Even when the paper is focused on using BERT for re-Ranking, the whole process has three steps that help filtering the passages.
Using elastic search I decided to implement the first step too, mainly because independently of which model I end up using (BERT or GPT2) I can’t compute everything on 6 million embeddings and have a reasonable runtime. Well, now is me against the clock, wish me luck!
2 Comments
6/27/2019 09:08:07 pm
The final stretch toward a project is always going to be tough. I mean, just think about all the effort and energy that you have spent trying to perfect that very project, then seeing it end all at once. It is both a proud and a sad moment for you, I guarantee that. I have my fair share of experiences when it comes to this scenario. It is truly an inspiring moment that will keep you wanting to do more projects. 6/27/2023 01:04:04 am
Thanks for sharing a very informative and knowledgeable blog I like it. Leave a Reply. |
