|
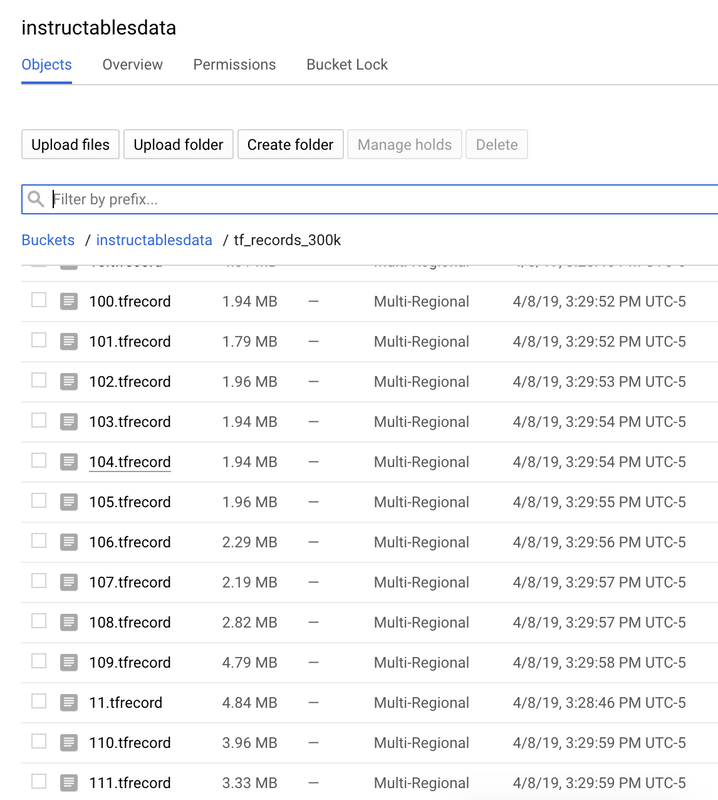
This week I used my new data, 70,000 (from the 300,0000) articles from Instructables to play with ELMO, TF-IDF and perform a Cosine Similarity. The results were much better! While making my data "trainable" I read a lot of articles that explain how cleaning and massaging the data can be 80% of the work in ML. This was a great lesson. Overall process:
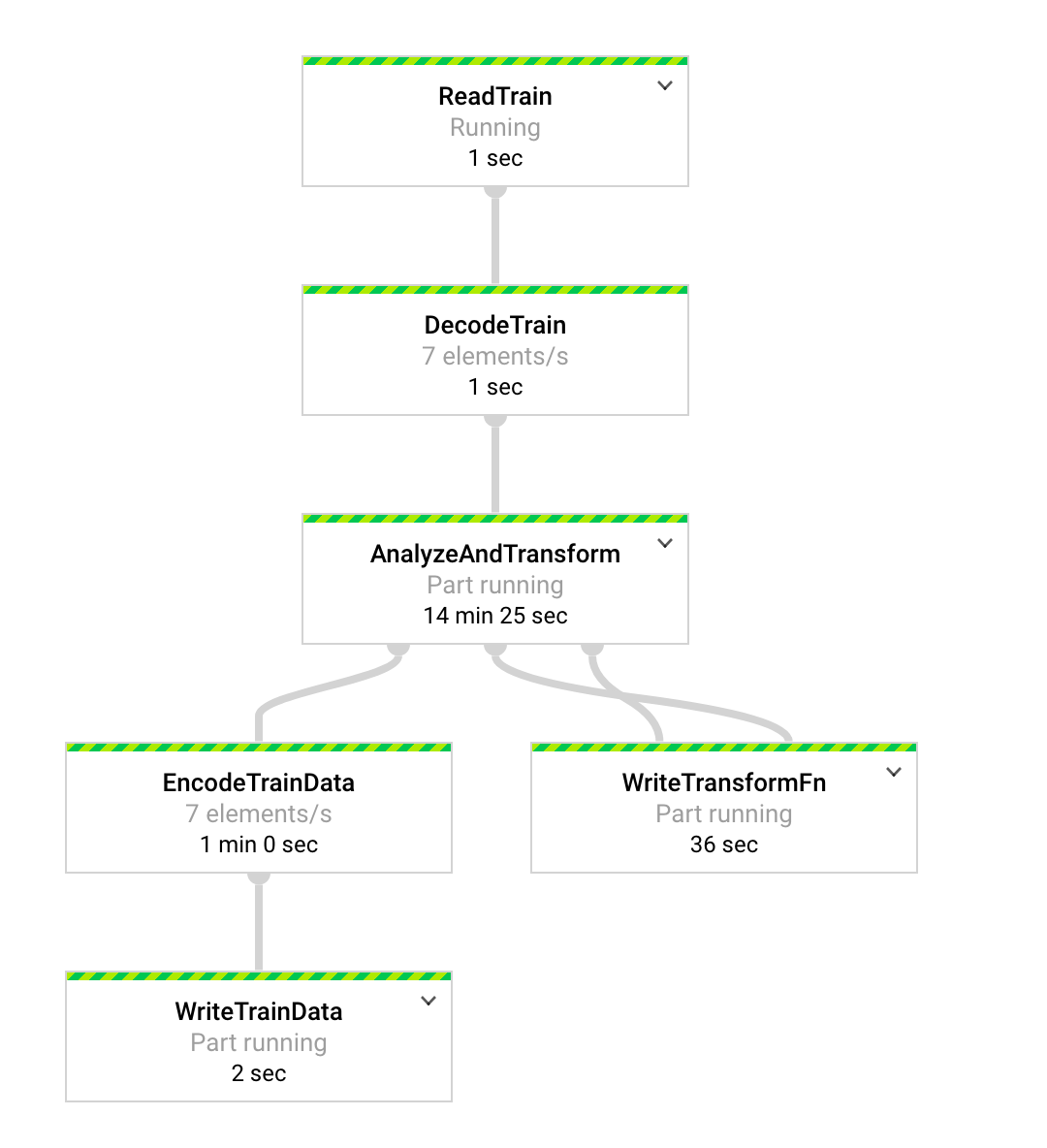
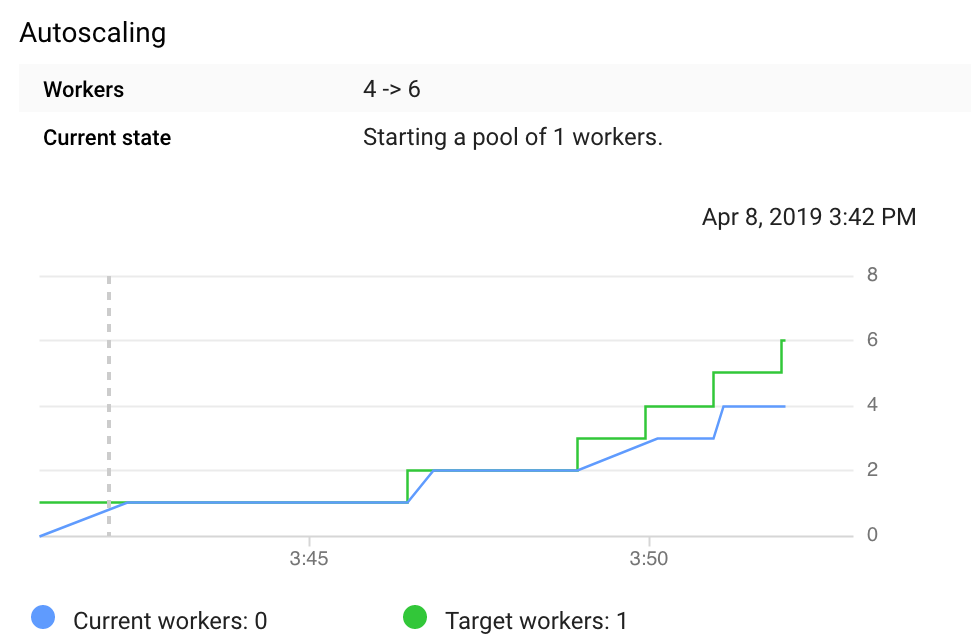
 I used tf.transform, tf.record and tf.example for the last three steps (preprocessing , design a dataset, load it and store it). I picked tf.transform and tf.record (tf.example is part of tf.record), because I wanted to learn something that was easily scalable, could integrate with my colab notebook, allow for parallel processing and monitoring.
1 Comment
10/29/2023 10:08:07 am
I wanted to express my gratitude for your insightful and engaging article. Your writing is clear and easy to follow, and I appreciated the way you presented your ideas in a thoughtful and organized manner. Your analysis was both thought-provoking and well-researched, and I enjoyed the real-life examples you used to illustrate your points. Your article has provided me with a fresh perspective on the subject matter and has inspired me to think more deeply about this topic. Leave a Reply. |