|
If you are new to ML (like me), you are probably reading cool papers and wondering how to implement those papers yourself, this blog is for you. I’m implementing DeepMind’s paper: Learning to Make Analogies by Contrasting Abstract Relational Structure and I’ll describe my process. This paper was suggested by my mentor Kai Arulkumaran after my exploration on Ratios and Proportions. The paper is really interesting, it shows a method to help deep neural network models to make analogies. The method is not based on a sophisticated architecture, but on what data is presented to the model. They presented contrasting cases that made abstract relational structures more salient and forced the model to learn them. The ability to make analogies is a cornerstone of human learning, intelligence and creativity. I found extremely interesting that even simple architectures of deep neural network models can learn to perform analogies. Humans learn in similar way, in the learning sciences this way of learning is known as: Contrasting Cases (very similar, ah!). It's a well-research method which consist in presenting similar sets of examples that help people notice features they might otherwise overlook. This learning method in humans increases the precision and usability of knowledge. The easiest possible case for coding a paper is if you find a paper that has the code, data and some results that can help you understand if you implemented it correctly. Mine didn’t have the code but it had the data, and I found code from their earlier paper: Measuring Abstract Reasoning in Neural Networks. Even when you can see the code you might not understand what’s happening with transformations and reshaping of data, neither with the main ideas of the paper, until you code it. To code it, depending on how old the paper is, you might need to go to the referenced papers and gather more information. So I went through the rabbit hole, first with the previous paper: Measuring abstract reasoning in neural networks. This paper explained how the data was generated and describes important details about the model's architecture from the paper I wanted to implement. 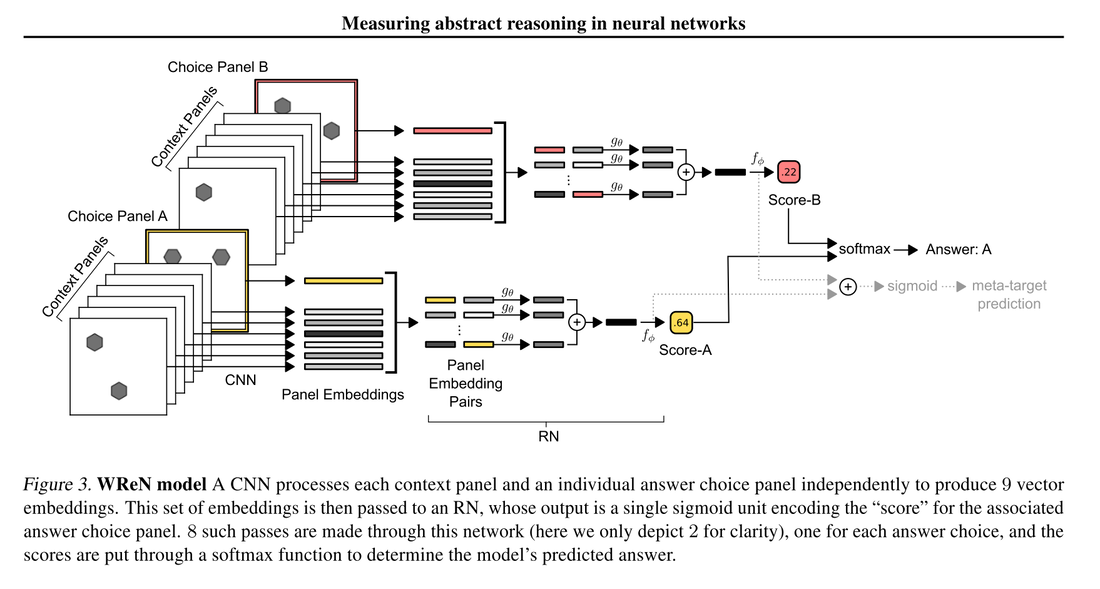
At this point is a good idea to hit the whiteboard (or piece of paper like me) and draw the architectures in the finest possible detail. This will help you to figure out what you understand and what you don’t. After some time, I realized I needed to go back to the rabbit hole, and find out more about Relational Networks. I browsed three more very interesting papers and I decided to start coding. I used Colab for this part, you can see my work-in-progress architecture code here. I recommend to start with your own self-generated data until most details are hashed out. In this way you can test things faster. Try not to code the easiest part of the model first but the parts that you need to understand better. Once you have that the rest just flows. After some effort and many coding cells I thought I had most of the architecture clarified. Now the real job begins: Plumbing! Coding complex models is a lot about piping data:
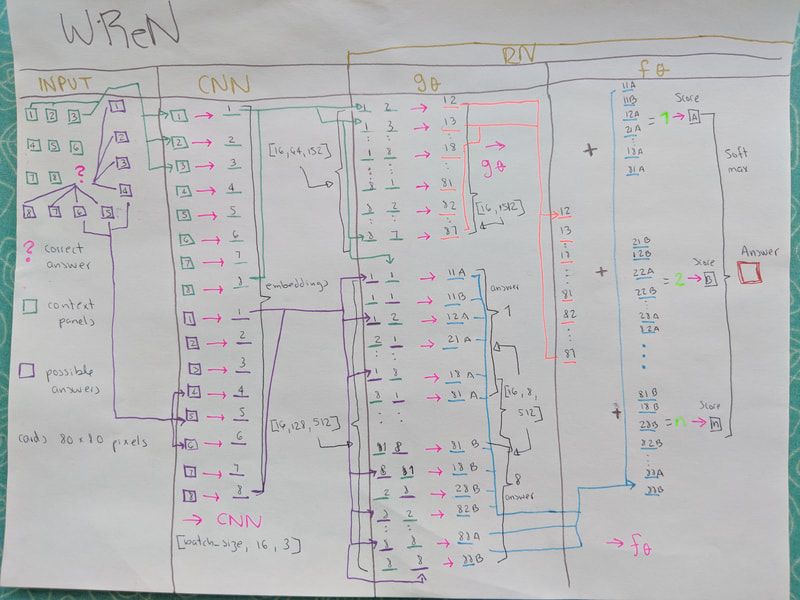 My final architecture sketch.
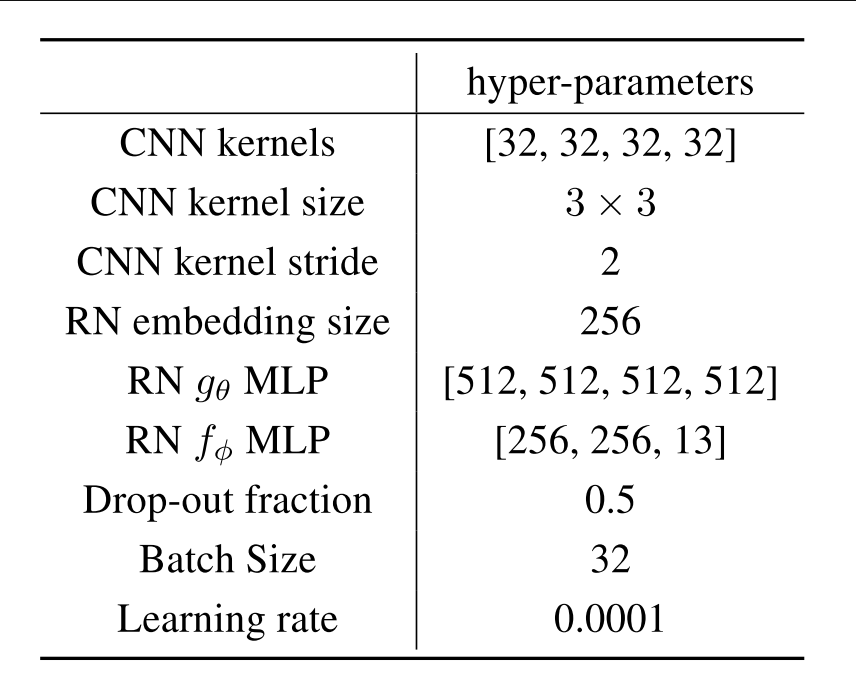
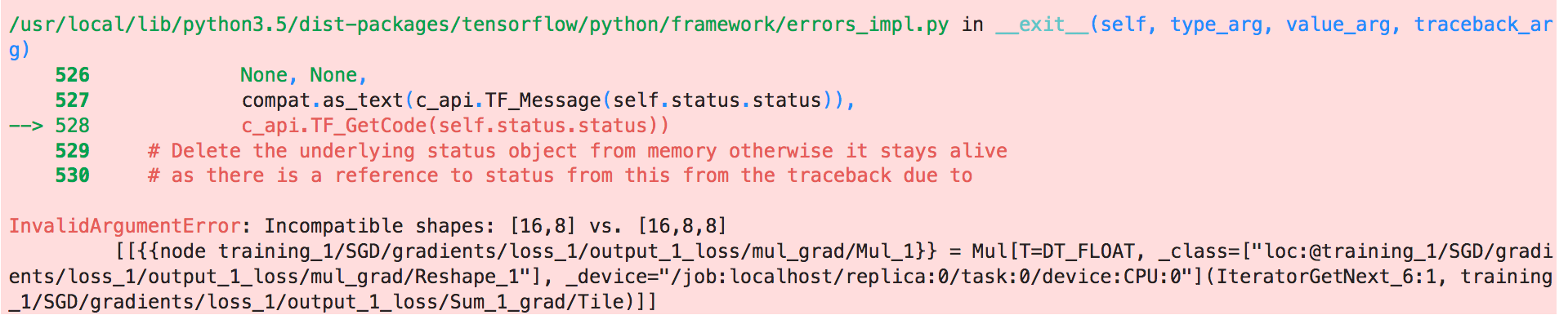
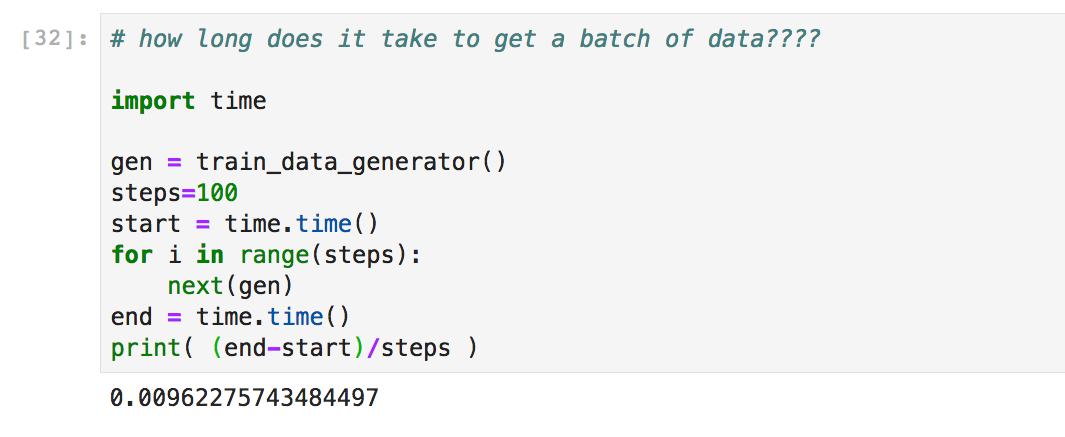
Eventually I got the right architecture with the correct size of pipes. The next challenge was getting the data and feeding it to the model. DeepMind has the data public, I downloaded some of it to GCP and opened an instance of a pretty fast machine :) Got my Jupiter notebooks ready and started the testing. Through a very easy and not super sophisticated test I found out that the way in which I was loading the data was too slow. I have two options now, either load the data in parallel or preprocess it... what would it be?? Loading the data in parallel is faster to implement and run, and can be great for experimentation but if I'm going to keep playing with this data it's better to preprocess it and store it on disk, even it takes longer to run and implement.
At this point I'm still deciding what to do. As you can see, implementing a paper with a complicated architecture can be a long process. But I'm learning a lot in the way: I'm learning to set my workflow, how to plan, implement and test an architecture. And most importantly getting a feeling of what a good plumber am I, and where I need to improve :)
1 Comment
|



 RSS Feed
RSS Feed
