|
If you are new to ML (like me), you are probably reading cool papers and wondering how to implement those papers yourself, this blog is for you. I’m implementing DeepMind’s paper: Learning to Make Analogies by Contrasting Abstract Relational Structure and I’ll describe my process. This paper was suggested by my mentor Kai Arulkumaran after my exploration on Ratios and Proportions. The paper is really interesting, it shows a method to help deep neural network models to make analogies. The method is not based on a sophisticated architecture, but on what data is presented to the model. They presented contrasting cases that made abstract relational structures more salient and forced the model to learn them. The ability to make analogies is a cornerstone of human learning, intelligence and creativity. I found extremely interesting that even simple architectures of deep neural network models can learn to perform analogies. Humans learn in similar way, in the learning sciences this way of learning is known as: Contrasting Cases (very similar, ah!). It's a well-research method which consist in presenting similar sets of examples that help people notice features they might otherwise overlook. This learning method in humans increases the precision and usability of knowledge. The easiest possible case for coding a paper is if you find a paper that has the code, data and some results that can help you understand if you implemented it correctly. Mine didn’t have the code but it had the data, and I found code from their earlier paper: Measuring Abstract Reasoning in Neural Networks. Even when you can see the code you might not understand what’s happening with transformations and reshaping of data, neither with the main ideas of the paper, until you code it. To code it, depending on how old the paper is, you might need to go to the referenced papers and gather more information. So I went through the rabbit hole, first with the previous paper: Measuring abstract reasoning in neural networks. This paper explained how the data was generated and describes important details about the model's architecture from the paper I wanted to implement. 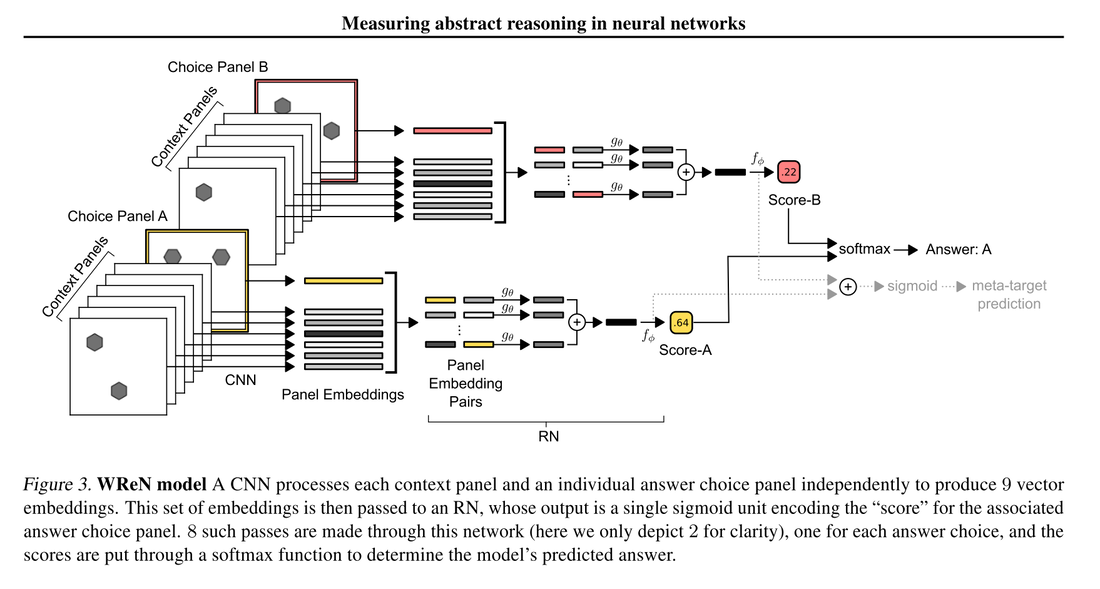
At this point is a good idea to hit the whiteboard (or piece of paper like me) and draw the architectures in the finest possible detail. This will help you to figure out what you understand and what you don’t. After some time, I realized I needed to go back to the rabbit hole, and find out more about Relational Networks. I browsed three more very interesting papers and I decided to start coding. I used Colab for this part, you can see my work-in-progress architecture code here. I recommend to start with your own self-generated data until most details are hashed out. In this way you can test things faster. Try not to code the easiest part of the model first but the parts that you need to understand better. Once you have that the rest just flows. After some effort and many coding cells I thought I had most of the architecture clarified. Now the real job begins: Plumbing! Coding complex models is a lot about piping data:
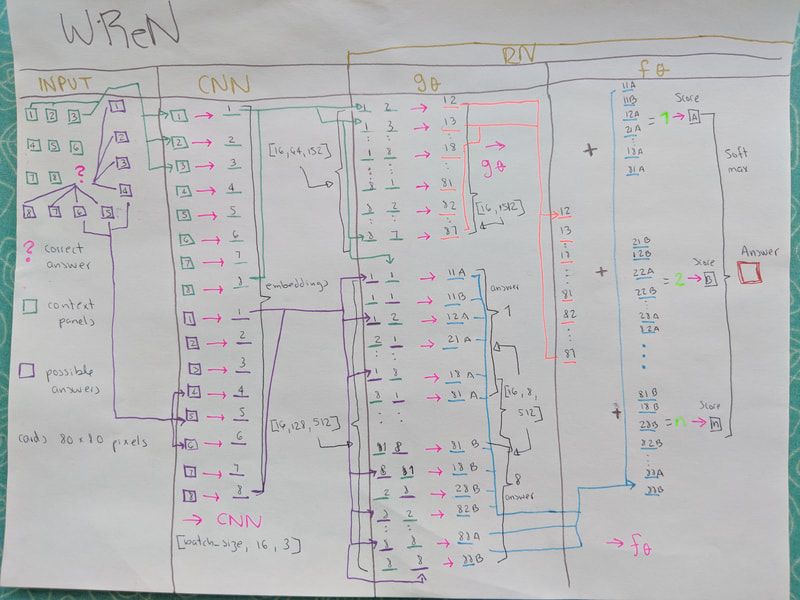 My final architecture sketch.
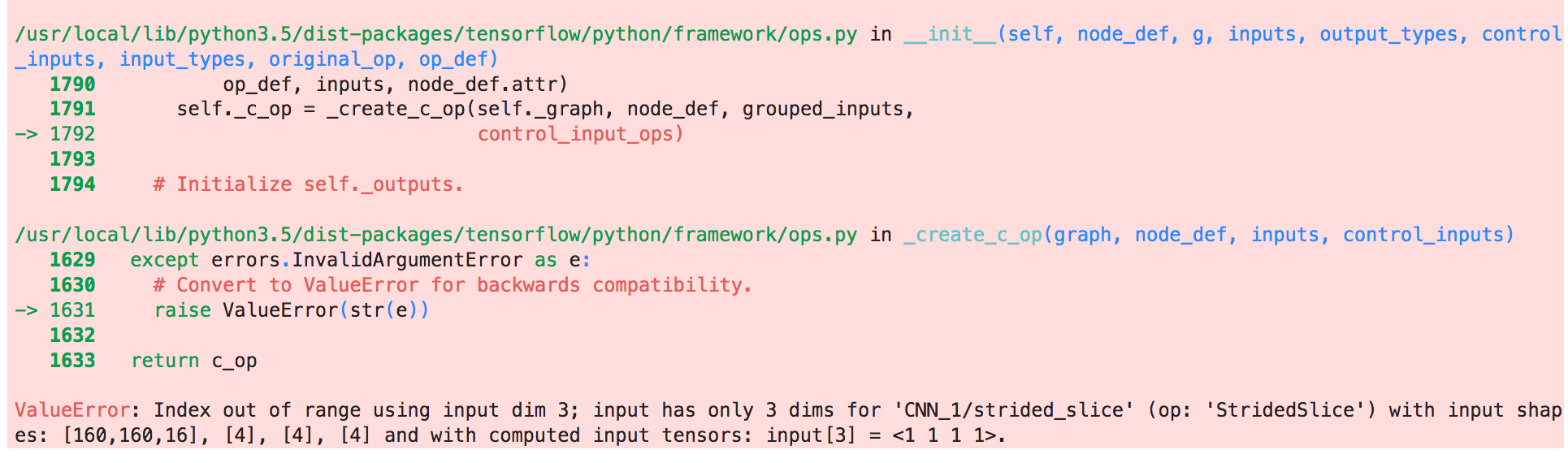
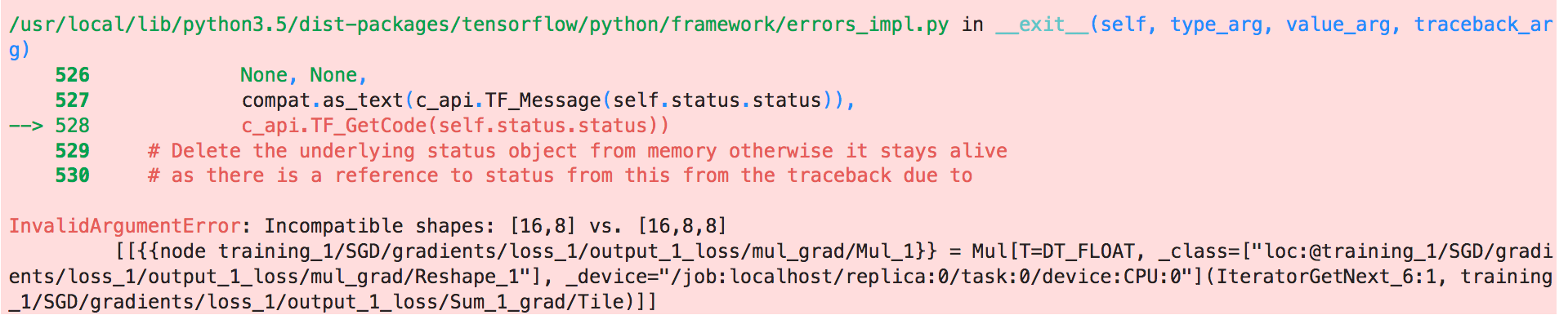
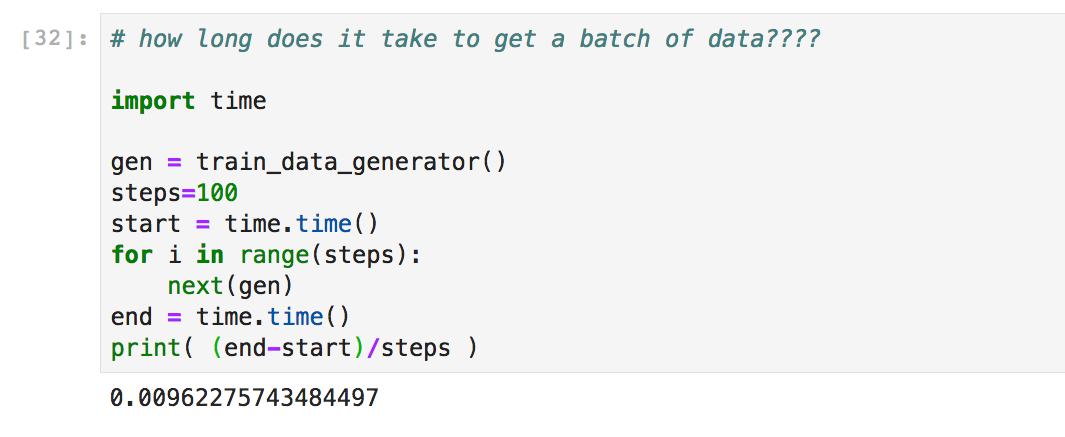
Eventually I got the right architecture with the correct size of pipes. The next challenge was getting the data and feeding it to the model. DeepMind has the data public, I downloaded some of it to GCP and opened an instance of a pretty fast machine :) Got my Jupiter notebooks ready and started the testing. Through a very easy and not super sophisticated test I found out that the way in which I was loading the data was too slow. I have two options now, either load the data in parallel or preprocess it... what would it be?? Loading the data in parallel is faster to implement and run, and can be great for experimentation but if I'm going to keep playing with this data it's better to preprocess it and store it on disk, even it takes longer to run and implement.
At this point I'm still deciding what to do. As you can see, implementing a paper with a complicated architecture can be a long process. But I'm learning a lot in the way: I'm learning to set my workflow, how to plan, implement and test an architecture. And most importantly getting a feeling of what a good plumber am I, and where I need to improve :)
1 Comment
Growing up in a catholic family I visited a lot of churches anyplace we traveled. All of them had a similar pattern, a very tall door and huge ceiling. As I child I wondered often, why all that empty space? Why is the ceiling so far and the door so tall? Eventually I came to the conclusion that it was for the visitors to experience our proportion in relation to a huge idea such as God.
Later in life I became very interested in the concept of proportion and I started seeing it everywhere: architecture, design, math, art, biology, music, astronomy, monetary transactions, and poetry. I understood the obsession that the Greeks and other ancient cultures had around them. Learning more about living systems such as animals and plants I found cases where those living systems can detect the size of other things with respect to their own. I wondered: does understanding the idea of proportions depends on having a body? Proportions and ratios are very powerful ideas, but they can be hard to learn. Especially because we mostly teach them in terms of math, which is more formal and less experiential. Children can understand that a smaller cat has the same body proportions as a bigger cat. But it's harder to understand that we can create a Roman temple based on the golden ratio, and that the proportion of that temple are the same as the one on the a shell. In between the cats and the temple, there seems to be an understanding gap.
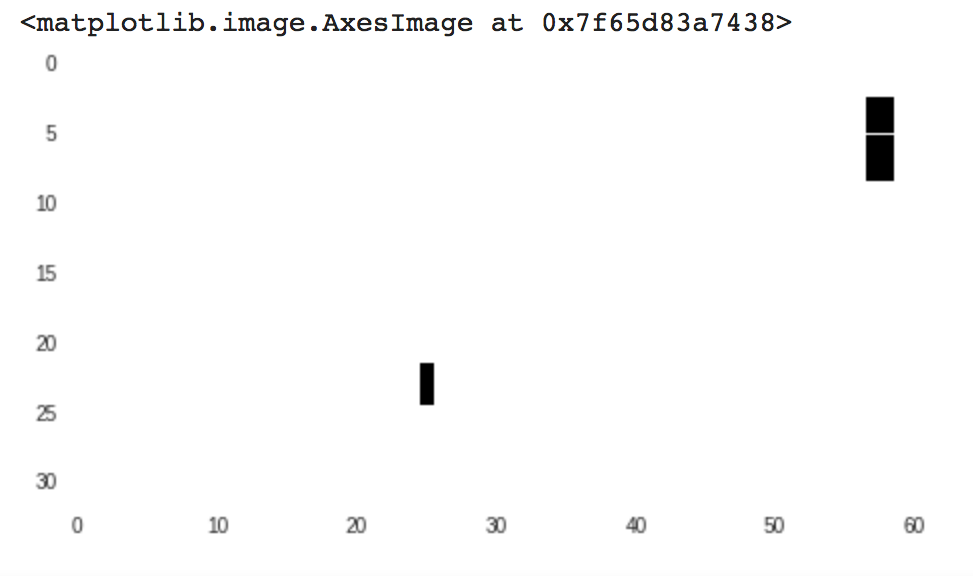
Proportion is also a concept we can study from the perspective of AI: Can AI learn the concept of proportion, and if it can, does it make the same kinds of generalizations and mistakes as humans? To start answering this question, I tried two very simple ways to train models to recognize proportions. The first experiment trains a model to recognize a 1:1 proportion between the height and width of a rectangle, by simple distinguishing between squares and non-square rectangles. The second experiment attempts to train the model to recognition proportions between two distinct rectangles. I wanted to know if rectangles that are closer to squares, because their width and height are not that different, e.g. 3:4, were harder to classify as rectangles. And does rotation matter? Will "standing" rectangles be harder to classify than "lying" rectangles, even if the difference between their width and height is the same (7:2 vs 2:7)? I decided that the easiest way to get data for this experiment was to create it. The data generating function returns a matrix with either a square or rectangle of randomly different sizes in different positions in the matrix. Example (see image below): a rectangle formed by the number 1, of width 5 and height 8. 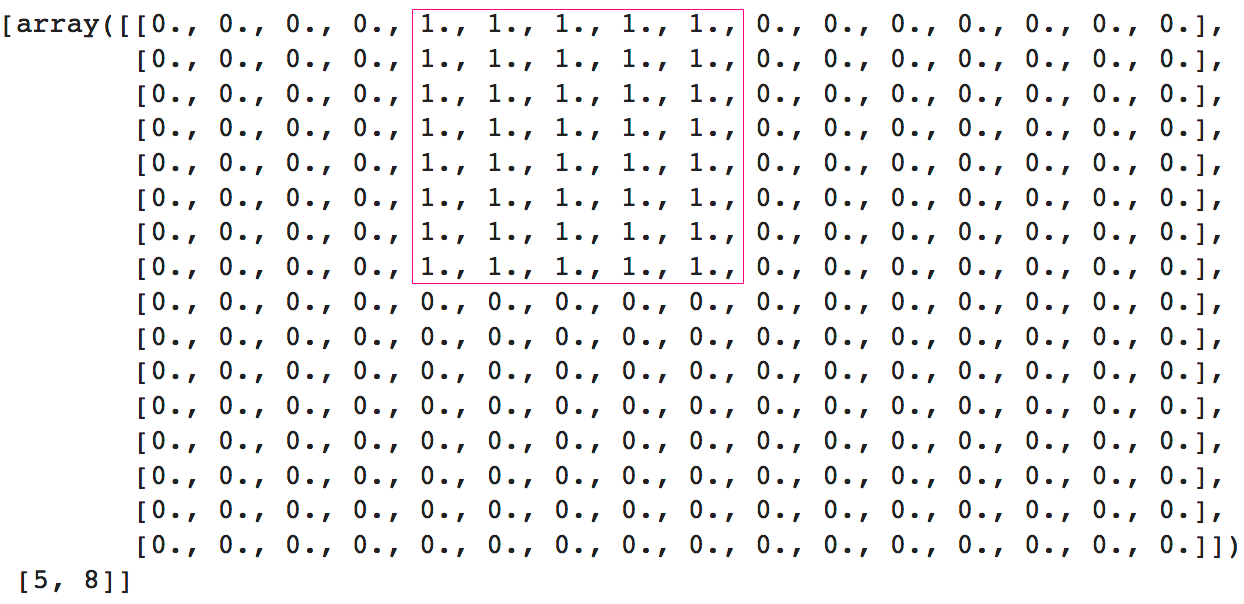 The training and validation set was half squares and half rectangles. Because I used supervised learning I had to label the data I created: I labeled all the squares as 1 and all the rectangles as 0. Creating data this way is easy and convenient because all the information you give a neural network to be trained with will eventually became a number (pictures into RGB numbers, sensing data, etc). By creating the raw input I was able to stop worrying about size, color, number, and balance of the data. If I had had to collect this dataset from images on the Web, it would have been much harder to find an equal number of squares and rectangles of specific sizes, colors, image dimensions, etc. Using Keras I constructed a neural network and then I trained it with the data I created. Then I created another random set of squares and rectangles and asked the model to classify those images as 1 or 0.
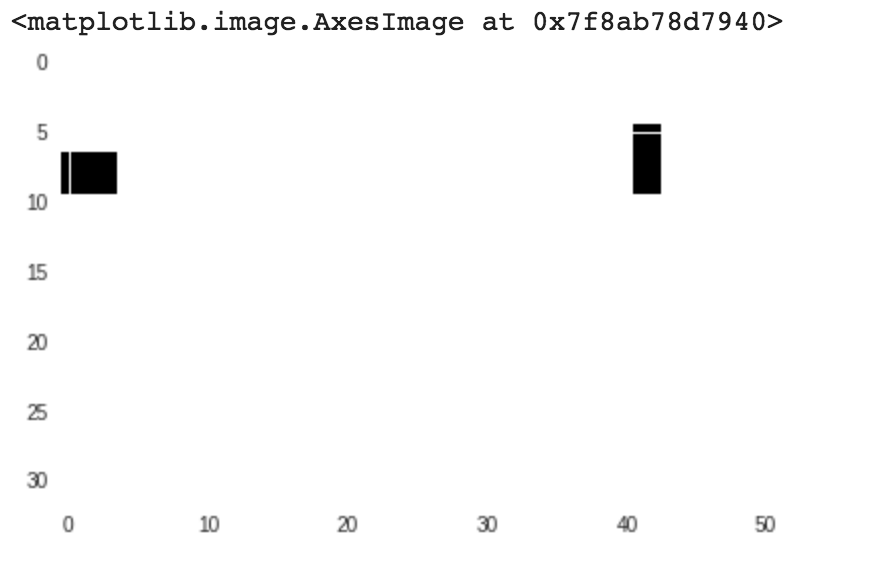
I wonder how much can this model generalize? I thought it will be interesting to see if the model could be trained more directly on proportion and less on the specific differences between rectangles and squares. So I created data that has two rectangular shapes. In one half of the data, the shapes will have the same proportion between their width and height, equal ratios (figure below on the left), and in the other half the data the proportion will be different (figure below on the right). Compared to the first model, we are not trying to recognize any 'special' proportion, but rather distinguishing between proportional relations between two objects vs non-proportional relations.
The accuracy of the model was very inconsistent, in ~65% of the cases the classification was correct. Meaning, just a smidge above chance. This is consistent with a human learning process, even when children have no problem classifying between squares and rectangles the idea of correctly classifying set of shapes with equal proportions from those with different proportions is much harder.
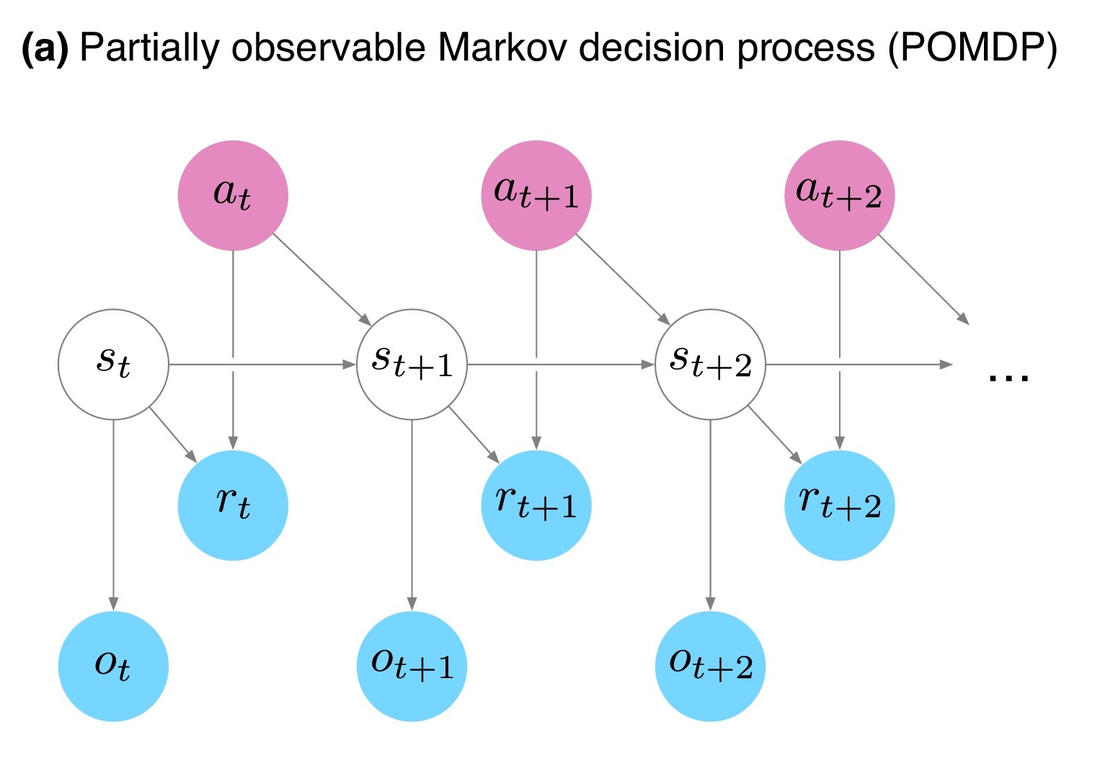
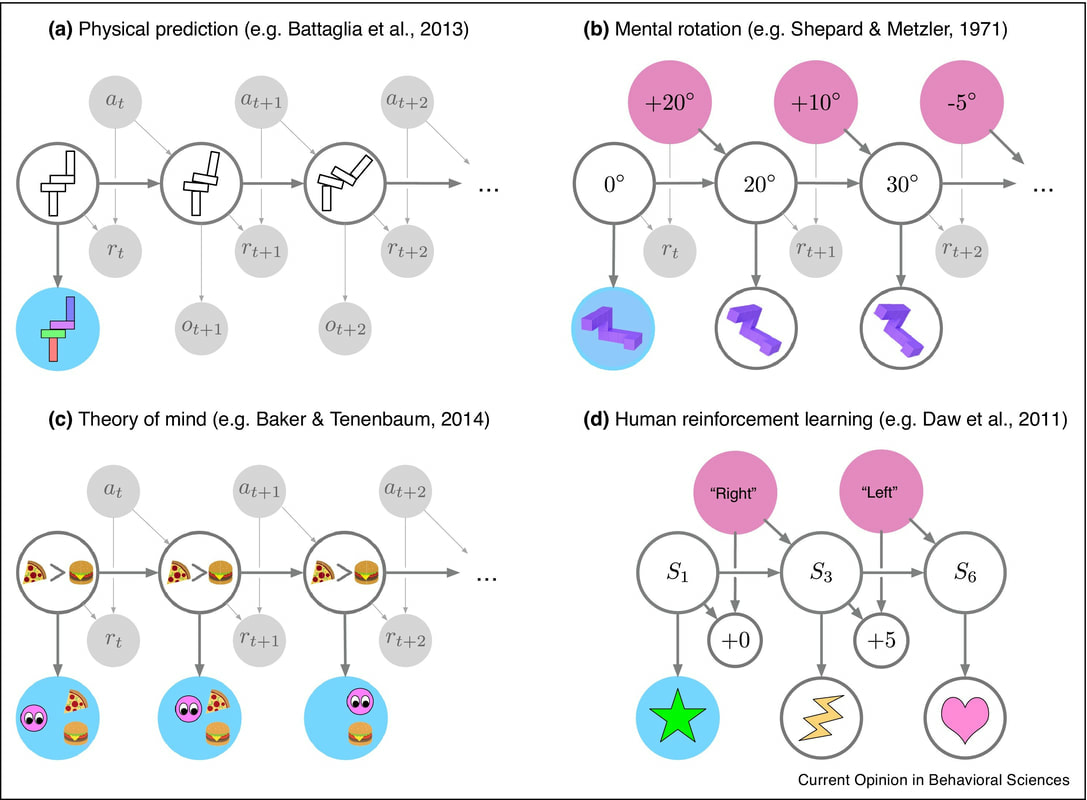
After getting the confusion matrix, which tells me the number and type of images that were incorrectly classified it seemed like the non-proportional rectangles were more difficult to classify correctly. Interesting... but much more experimentation is necessary to understand what's going on in this model. Maybe next week I will have some insights :) Feb 4-8 This week I read Analogues of mental simulation and imagination in deep learning. There so much to talk about in that paper but let's start with a core concept of RL, POMDP. POMDP is exciting to me because I believe it represents human-decision-making well enough to see how far it can take AI to meet our own human decision process. I'll keep talking about it in the next posts. The paper's background is that we can think of two types of computational approaches to intelligence: i) Statistical pattern recognition, which focuses mostly in prediction (classification, regression, task control) and ii) model-building, which focuses in creating models of the world (to explain what we see, to imagine what could have happened that didn’t, or what could be true that isn’t, and then planning actions to make it so). The paper talks about the second approach, deep learning methods for constructing models from data and learning to use them via reinforcement learning (RL), and compares such approaches to human mental simulation. RL is about agents taking actions in an environment to maximize a cumulative reward. The way RL represents this process is through something called the Partially-Observable Markov Decision Process (POMDP). Let me explain: RL is the closest AI has to human behavior. We are the agents in an environment from which we know some part of it (partially-observable) and we make decisions that translate into actions with the hope to gain something (money, time, love, peace of mind, etc). But for this process to be computable, RL represents it as a POMDP. Which is a mathematical framework for dealing with a decision process where the outcomes are partially random and partially in control of the decision maker. POMDP is super cool and worth understanding, because it provides a useful framing for a variety of mental simulation phenomena. It illustrates how behaviors that seem quite different on the surface share a number of computational similarities. These are graphs from the paper. In the right graph we can see examples of how to use POMDP to represent human-mental-models. I'll explain first the graph on the left, which is a diagram of POMDP. Then I'll use it to see one example from the right graph. Let's look at the left graph. s is the environment state, a full description of the world which the agent can't directly observe, a the action taken on the state of the world made by the agent, a is the only variable that can be intervened on. o is the observation of the environment directly perceived by the agent, r is a number that represents the reward which tells the agent how well its doing in the task, and that can be also observed by the agent, and t time. The arrows represent dependencies. Basically there is a state st (s at time t) that will influence ot, rt, st+1. But at starts independent of st and then also influence rt and st+1. Then the cycle repeats. Some examples of human model simulation (physical prediction, mental rotation, theory of the mind, human reinforcement learning) can be seeing on the right graph. Even-though they are different all of them can be represented by a POMDP. I'll explain (c) Theory of the mind. Theory of the mind is the ability to attribute mental states—beliefs, intents, desires, emotions, knowledge, etc.—to oneself, and to others, and to understand that others have beliefs, desires, intentions, and perspectives that are different from one's own. This example represents the thought process of an agent A while it tries to figure out if agent B desires to eat pizza or hamburger. Let's assume that A is behind B in a street where the pizza restaurant is before the hamburger restaurant. A can see in which restaurant B will get in. A starts by thinking that is more probable that B will want to eat pizza (maybe A likes pizza more). A can observe Blooking at both restaurants (t), then A sees B walking towards the pizza place (t+1). If B get's into the restaurant then A can decide that B desires pizza more than hamburger, but if B keeps walking and get's inside the hamburger restaurant A will decide that B desires hamburgers more.
|






 RSS Feed
RSS Feed
